Join Transform 2021 for the most crucial styles in business AI & & Data. Learn more.
AI is dealing with a number of crucial obstacles. Not just does it need big quantities of information to provide precise outcomes, however it likewise requires to be able to make sure that information isn’t prejudiced, and it requires to adhere to significantly limiting information personal privacy guidelines. We have actually seen a number of services proposed over the last number of years to attend to these obstacles– consisting of different tools created to determine and decrease predisposition, tools that anonymize user information, and programs to make sure that information is just gathered with user approval. However each of these services is dealing with obstacles of its own.
Now we’re seeing a brand-new market emerge that assures to be a conserving grace:synthetic data Artificial information is synthetic computer-generated data that can stand-in for information gotten from the real life.
An artificial dataset must have the same mathematical and statistical properties as the real-world dataset it is changing however does not clearly represent genuine people. Consider this as a digital mirror of real-world information that is statistically reflective of that world. This makes it possible for training AI systems in an entirely virtual world. And it can be easily tailored for a range of usage cases varying from health care to retail, financing, transport, and farming.
There’s substantial motion occurring on this front. More than 50 vendors have actually currently established artificial information services, according to research study last June by StartUs Insights. I will lay out a few of the leading gamers in a minute. Initially, however, let’s take a better take a look at the issues they’re assuring to fix.
The difficulty with genuine information
Over the last couple of years, there has actually been increasing concern about how fundamental biases in datasets can unsuspectingly result in AI algorithms that perpetuate systemicdiscrimination In reality, Gartner predicts that through 2022, 85% of AI tasks will provide incorrect results due to predisposition in information, algorithms, or the groups accountable for handling them.
The expansion of AI algorithms has actually likewise caused growing issues over information personal privacy. In turn, this has actually caused more powerful customer information personal privacy and defense laws in the EU with GDPR, along with U.S. jurisdictions consisting of California and most recently Virginia.
These laws offer customers more control over their individual information. For instance, the Virginia law grants consumers the right to gain access to, appropriate, erase, and acquire a copy of individual information along with to pull out of the sale of individual information and to reject algorithmic access to individual information for the functions of targeted marketing or profiling of the customer.
By restricting access to this info, a specific quantity of specific defense is acquired however at the expense of the algorithm’s efficiency. The more information an AI algorithm can train on, the more precise and reliable the outcomes will be. Without access to sufficient information, the advantages of AI, such as helping with medical diagnoses and drug research study, might likewise be restricted.
One option frequently utilized to balance out personal privacy issues is anonymization. Individual information, for instance, can be anonymized by masking or removing determining qualities such as eliminating names and charge card numbers from ecommerce deals or eliminating determining material from health care records. However there is growing proof that even if information has actually been anonymized from one source, it can be associated with customer datasets exposed from security breaches. In reality, by integrating information from numerous sources, it is possible to form a remarkably clear picture of our identities even if there has actually been a degree of anonymization. In some circumstances, this can even be done by correlating data from public sources, without a wicked security hack.
Artificial information’s option
Artificial information assures to provide the benefits of AI without the drawbacks. Not just does it take our genuine individual information out of the formula, however a basic objective for artificial information is to carry out much better than real-world information by correcting bias that is frequently engrained in the real life.
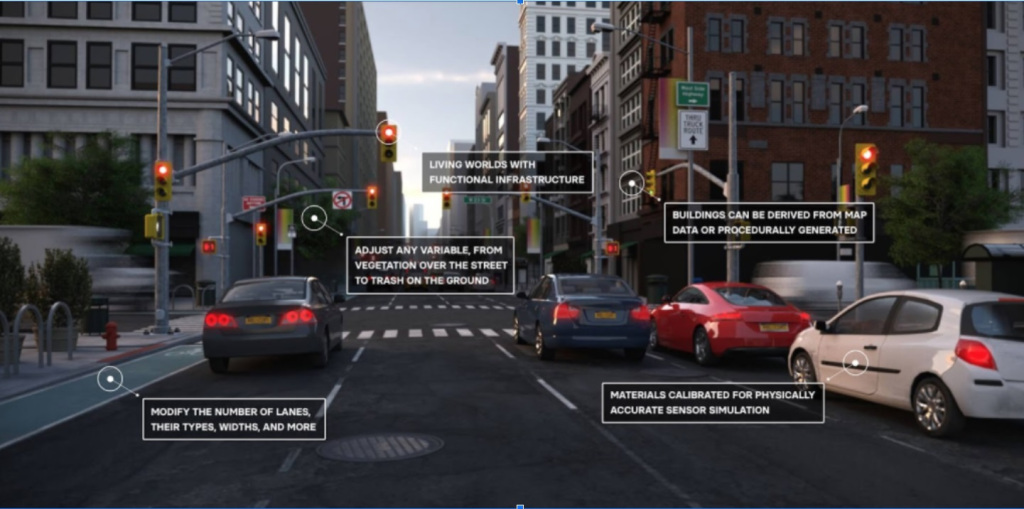
Although suitable for applications that utilize individual information, artificial info has other usage cases, too. One example is intricate computer system vision modeling where lots of aspects connect in genuine time. Artificial video datasets leveraging innovative video gaming engines can be developed with hyper-realistic images to represent all the possible scenarios in a self-governing driving circumstance, whereas attempting to shoot images or videos of the real life to catch all these occasions would be not practical, possibly difficult, and most likely harmful. These artificial datasets can considerably accelerate and enhance training of self-governing driving systems.

Possibly paradoxically, among the main tools for developing artificial information is the very same one utilized to produce deepfake videos. Both utilize generative adversarial networks (GAN), a set of neural networks. One network creates the artificial information and the 2nd attempts to find if it is genuine. This is run in a loop, with the generator network enhancing the quality of the information till the discriminator can not inform the distinction in between genuine and artificial.
The emerging environment
Forrester Research study just recently determined a number of critical technologies, consisting of artificial information, that will comprise what they consider “AI 2.0,” advances that significantly broaden AI possibilities. By better anonymizing information and fixing for fundamental predispositions, along with producing information that would otherwise be tough to acquire, artificial information might end up being the conserving grace for lots of huge information applications.
Artificial information likewise features some other huge advantages: You can produce datasets rapidly and frequently with the information identified for monitored knowing. And it does not require to be cleaned up and kept the method genuine information does. So, in theory a minimum of, it features some big time and expense savings.
A number of reputable business are amongst those that create artificial information. IBM explains this as data fabrication, producing artificial test information to get rid of the threat of secret information leak and address GDPR and regulative concerns. AWS has actually established internal artificial information tools to create datasets for training Alexa onnew languages And Microsoft has actually established a tool in collaboration with Harvard with an artificial information ability that permits increased cooperation in between research study celebrations. Regardless of these examples, it is still early days for artificial information and the establishing market is being led by the start-ups.
To finish up, let’s have a look at a few of the early leaders in this emerging market. The list is built based upon my own research study and market research study companies consisting of G2 and StartUs Insights.
- AiFi— Utilizes artificially created information to replicate stores and consumer habits.
- AI.Reverie— Produces artificial information to train computer system vision algorithms for activity acknowledgment, item detection, and division. Work has actually consisted of wide-scope scenes like wise cities, unusual aircraft recognition, and farming, together with smart-store retail.
- Anyverse— Imitates circumstances to produce artificial datasets utilizing raw sensing unit information, image processing functions, and customized LiDAR settings for the vehicle market.
- Cvedia— Produces artificial images that streamline the sourcing of big volumes of identified, real, and visual information. The simulation platform utilizes numerous sensing units to manufacture photo-realistic environments leading to empirical dataset development.
- DataGen— Interior-environment usage cases, like wise shops, at home robotics, and enhanced truth.
- Diveplane— Produces artificial ‘twin’ datasets for the health care market with the very same analytical homes of the initial information.
- Gretel— Intending to be GitHub comparable for information, the business produces artificial datasets for designers that maintain the very same insights as the initial information source.
- Hazy— creates datasets to improve scams and cash laundering detection to fight monetary criminal offense.
- Mostly AI— Concentrate on insurance coverage and financing sectors and was among the very first business to produce artificial structured information.
- OneView— Establishes virtual artificial datasets for analysis of earth observation images by artificial intelligence algorithms.
Gary Grossman is the Senior VP of Innovation Practice at Edelman and International Lead of the Edelman AI Center of Quality.
VentureBeat
VentureBeat’s objective is to be a digital town square for technical decision-makers to get understanding about transformative innovation and negotiate.
Our website provides necessary info on information innovations and techniques to direct you as you lead your companies. We welcome you to end up being a member of our neighborhood, to gain access to:.
- current info on the topics of interest to you
- our newsletters
- gated thought-leader material and marked down access to our treasured occasions, such as Transform 2021: Learn More
- networking functions, and more





